目录
生物样本库管理软件的革命:告别内耗,用系统适应人
林睿诚
·
2025-10-28 17:35:00:47
阅读5分钟
已读2207次
当前生物样本库管理深陷效率泥潭,根源不在团队或市场,而在于过时的管理范式。本文揭示如何通过“零代码”驱动的范式变革,实现真正以人为核心的高效运营。
用户关注问题
零代码是否意味着功能受限?
很多人担心零代码平台不如传统软件强大,是否如此?
恰恰相反。零代码不是功能简化,而是能力前置。它通过可视化配置代替代码编写,使用户能自由组合字段、流程、权限和视图。在生物样本库场景中,这意味着你可以自主创建符合特定研究需求的采集表单、自动触发质控检查、生成定制化追溯报告,而无需依赖开发团队。功能深度由业务需求决定,而非技术壁垒。

现有数据能否顺利迁移?
我们已有大量历史数据存在不同系统中,迁移会不会很麻烦?
数据迁移的关键不在于工具,而在于结构设计。优秀的生物样本库管理软件会提供标准化的数据映射模板和批量导入接口,支持从Excel、CSV及常见数据库格式导入。更重要的是,它应具备灵活的元数据模型,能容纳不同来源的样本属性定义,并建立统一的唯一标识体系,确保历史数据与新流程无缝衔接。
如何证明这种系统真的提升效率?
听起来很好,但怎么知道它不是又一个华而不实的概念?
最有效的验证方式是设定可量化的基线指标。例如,在上线前记录样本入库平均耗时、数据纠错频率、报表生成周期等关键指标,运行三个月后重新测量。真正的价值体现在这些数字的显著改善。同时,观察一线人员是否主动减少使用Excel或纸质记录——这是系统被真正接纳的信号。
免责申明:本文内容通过 AI 工具匹配关键字智能整合而成,仅供参考,伙伴云不对内容的真实、准确、完整作任何形式的承诺。如有任何问题或意见,您可以通过联系 12345@huoban.com 进行反馈,伙伴云收到您的反馈后将及时处理并反馈。
热门内容
推荐阅读
最新内容
热门场景应用
用零代码轻松搭建,在⼀个平台上管理所有业务
超多模板 开箱即用
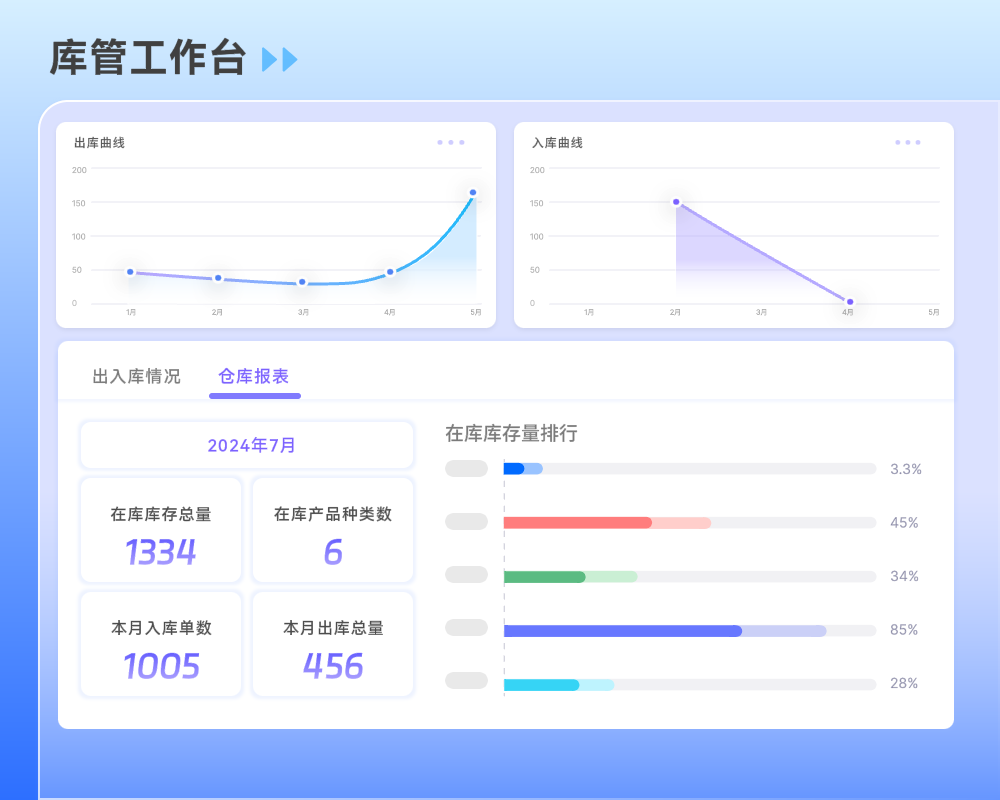
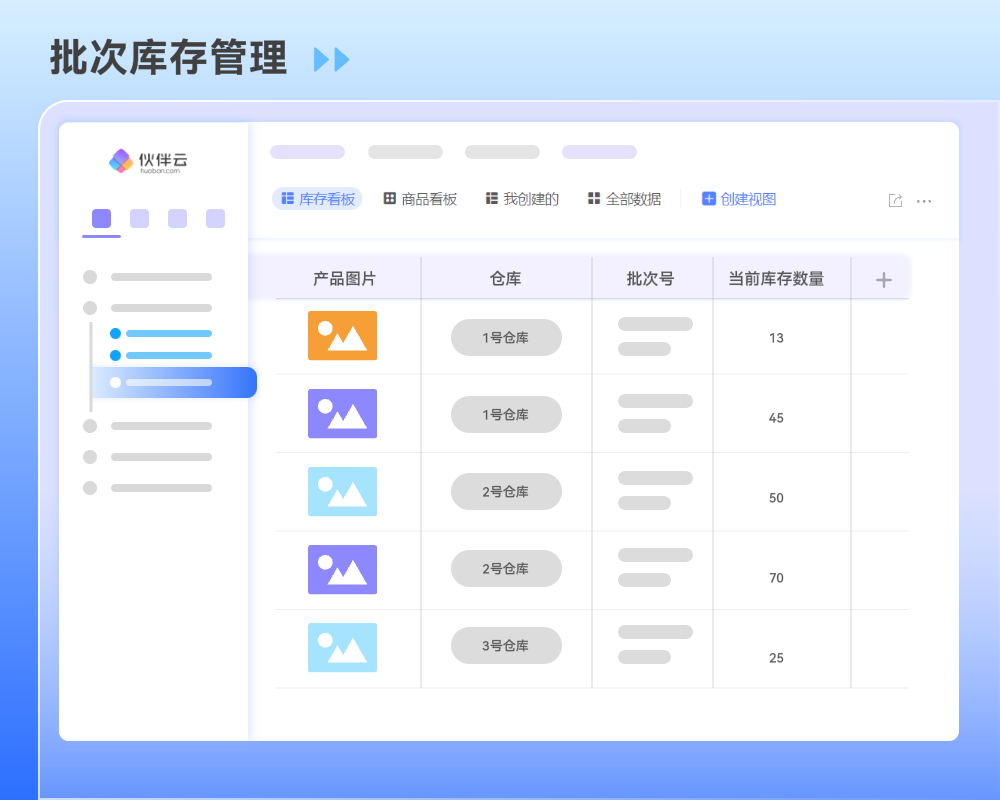


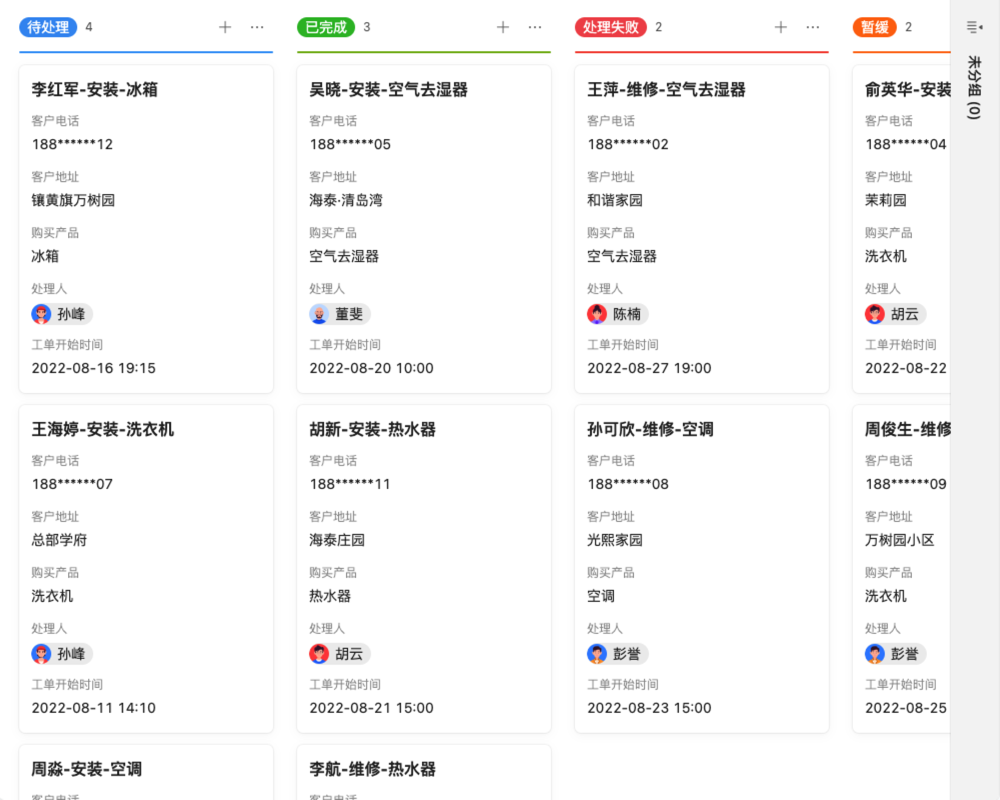

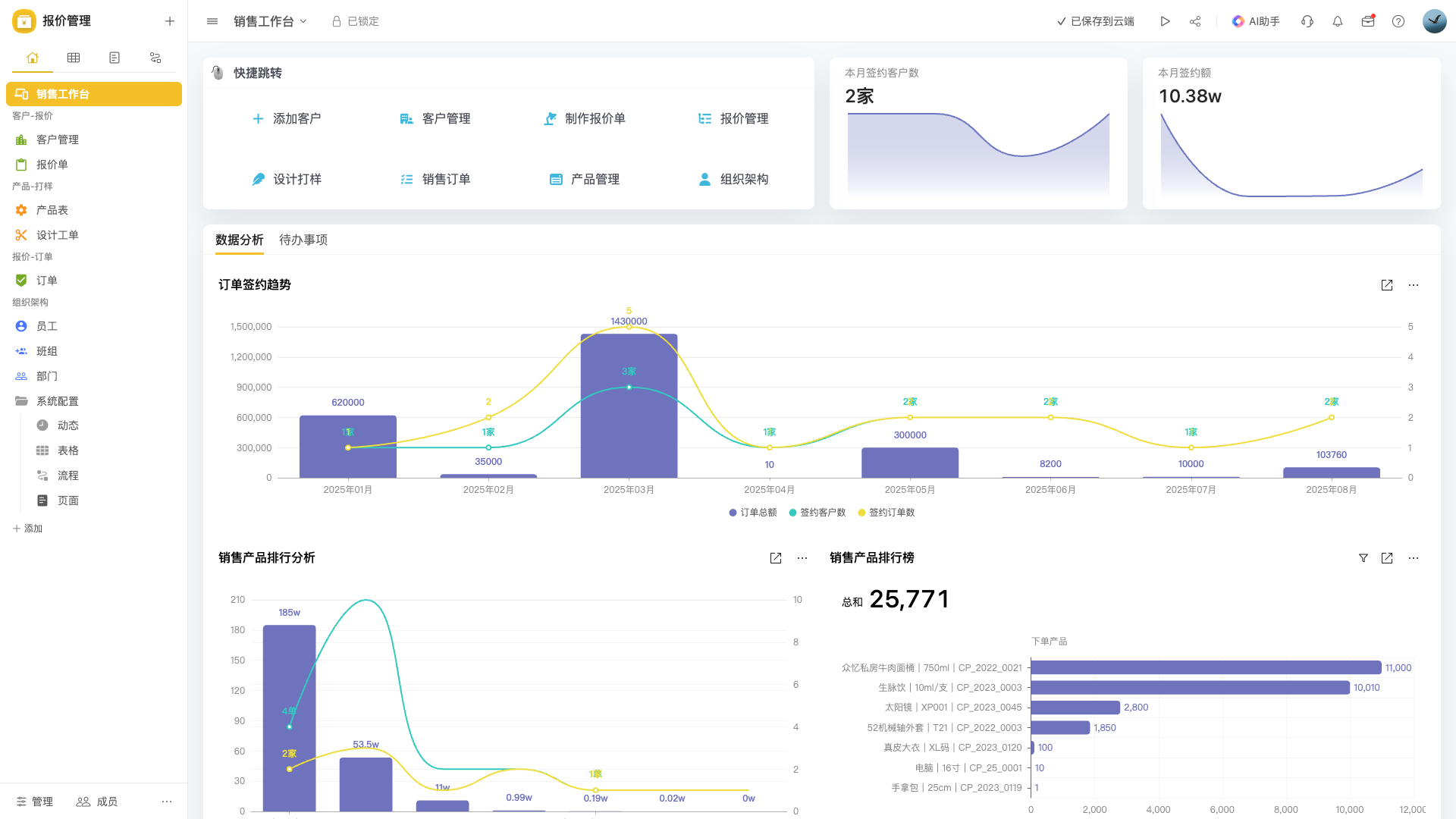

能陪你创业,也能陪你上市
300万用户都在使用伙伴云,他们在竞争中脱颖⽽出
成为每个组织数字化历程中最值得信赖的伙伴
服务千行百业,值得您信赖